



Introducing Neets TTS
by Martin Shkreli

In this space, we’ll talk about all things Neets going forward:
Updates on our product, news in the audio & LLM AI world, our positions on issues and so forth. This entry will be a little different since it is the first. The obvious question is: why make Neets?
Well, we were a client of both of whom we consider to be the best text-to-speech services. Both companies use the Tortoise diffusion model system. Both are obscenely expensive. Despite hating the idea that we should have to talk to a person, we reached out to leaders at both companies and didn’t hear back. So, we decided to try price decreases for a change and see if we could make something far cheaper.
Oh, if you don’t know what text-to-speech is, here are the basics: you input some text (through a front end or an API) and the output is audio. You can use this for a number of things: apps, websites, interactive voice response (IVR), video games, streams any place where the user may want to hear text instead of read it, content creation (those funny YouTubes and Tik Toks), etc.
The Rip Off
Here’s the math on text-to-speech pricing. Below is a screen shot from one competitor. If you pay enough, you get a volume discount of $330 for 40 hours, or $8.25/each. Imagine paying that and powering your whole website with it. For DrGupta, our first app, which is an AI physician, we wanted to have “Dr. Gupta” read out, using text-to-speech, his answers to users’ questions. With 100,000 users (your site may have 10x or 100x this!), our bill could have easily been over $1 million. Our OpenAI bill is a few thousand dollars. Which is the more innovative service?
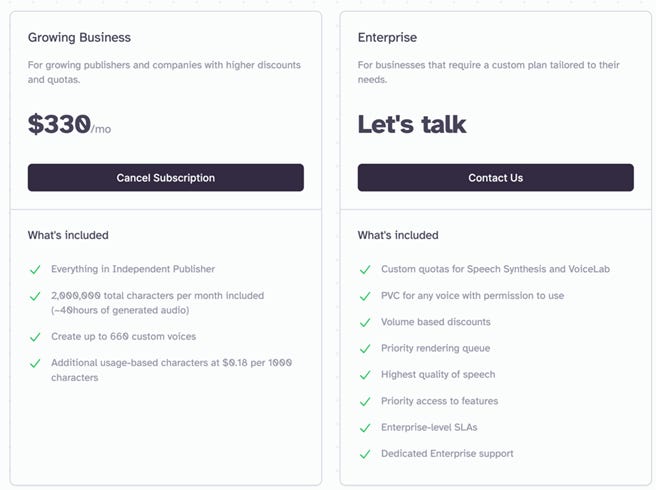
And what is up with “Let’s talk”? Who, in the history of software sales, has ever wanted to talk to some sleazy enterprise salesperson? Yeah, let’s talk about how we’re going to rip you off and make sure we give different prices to different customers based on their negotiating skills. Get outta here.
But, their actual service is great. The latency is good, the “cloning” (which is not really cloning but latent conditioning) is fast, the API is spotless. It’s a really great product, and I can’t knock them for that. But the price is just atrocious. Imagine if you made an AI “waifu”, and you wanted to talk to them all month long. Your OpenAI bill might be $10, but your TTS bill could be $1,000! That’s just crazy.
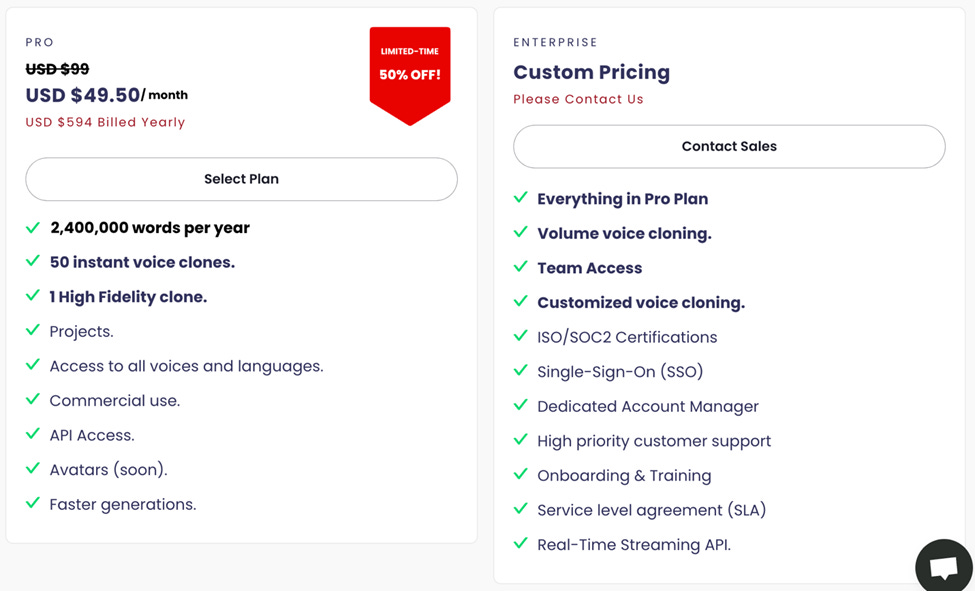
The other vendor is a little cheaper, I think:
So, if a word is 5 characters on average, one is 400,000 words for $330/month, or 1,212 words per $1. The other company is 2,000 words per $1, or almost 40% cheaper. One of the many problems with the other company is you only get one “voice clone” (again not a real clone, but more on that in a future blog post). If you want more voice clones you must email them. WTF?
You might say, “Well, Martin, what if these are the market rates and it just costs a lot of compute to do this? Just take a dose of your own medicine.” Let’s look at that. On one H100, we can serve four concurrent customers. Assume that inference time is equal to play time (it is MUCH faster, so this is a conservative assumption). One H100 at Lambda Labs is $2.00/hour. So, it costs us $0.50/hour of speech. At one company’s highest pricing tier, that is a 94% margin for them. This is without various speedups we are working on to make inference much faster (more on this in a second). A lower price isn’t just some competitive advantage. Lower prices will open the opportunity for scale use cases of TTS. If you have a website like Dr. Gupta, or a video game that has one million users, you can now or will soon be able to afford TTS without creating an overwhelming new cost.
What is TTS and why is this important?
The same way diffusion models changed image generation (Dalle-3, Stable Diffusion, Midjourney), diffusion models are changing audio generation. One brilliant man, James Betker, asked the question: “What if I take the approach Dall-E took to photos and try it on audio?”
Over a year, Betker worked on this side project he called Tortoise. He open-sourced some of it. If you want to play around and try to recreate it, you will run into some issues. We spent three months solving these issues, so you may be able to as well. Betker left a lot of notes and clues behind on how he did what he did, but also withheld some information. With a 4090 and enough know-how, you may be able to get Tortoise to work on your own. Good luck and let us know if you can.
Tortoise is complicated. Its two main components are a diffuser and a transformer. The transformer is literally GPT-2 and we can optimize it a lot further. We implemented various tools to speed up performance of the transformer. We are implementing a variety of tools to speed up diffusion, but they are not in production as of this release. There are three other machine learning-derived components of the Tortoise model, making it a true Frankenstein. The Vocoder Tortoise uses is BigVGAN, a generative adversarial network.
A major issue with Tortoise is Betker withheld VQ-VAE training code. We were able, thanks to Betker’s hints, train our own and fine-tune our own VQ-VAEs. We also took the suggestion of Tortoise-Fast and removed the CLVP neural network. There are a lot of places we can go to further Tortoise. If you are interested in helping or have your own ideas on how to accomplish improvements, feel free to reach out to me: martin@dl.software or on X @wagieEACC.
Where are we going? Last two miles.
We believe there are two last miles for text-to-speech, thanks to Betker’s incredible innovation. The first is latency and the second is dialogue modeling.
We believe we can get latency down to 100 milliseconds over time, with hopefully some immediate improvements in the weeks ahead. Right now, our latency is not great. On the plus side, reduced latency will mean lower costs for us, which we will try to pass through to you. If we can achieve this, we’d be talking about a 99% or even, someday, 99.9% lower price than our competition. If you need ultra-low latency, Tortoise may not be the best model for now. We may decide to field other models or even mixed models for these use cases. Stay tuned as we rapidly improve latency.
We also have a secret TTS improvement up our sleeve that no one has done. Stay tuned for that.
Right now, there is a very uncanny valley in text-to-speech. Some speech-to-text model (usually whisper) decodes the user’s speech to text or directly transmits text to a large language model. That large language model generates a text response. This is fed to a TTS API and then streamed to the user. There is no backchanneling, just silence while compute is churned. If that is more than 500 milliseconds, the effect is very odd, almost like a very long-distance phone call. Even if it is very fast, the lack of any noise whatsoever from the putative speaker is eerie and destroys immersion. We hope to release a real-time always-on dialogue agent at some point next year. This, in our opinion, is the true last mile in text-to-speech. After that, the robots have won.
The basics.
We will work hard to quickly backfill the basics: voice cloning and streaming.
We should have voice cloning up soon. The current competitors do something called “latent conditioning”, which is how they can “clone” voices with small amounts of audio. This is not real cloning. You must fine-tune to do real cloning. Think about it, how can you capture the corpus of someone’s prosody and intonation with a few minutes of their speech? Fine-tuning is expensive, but if you really want something that mimics the speaker, that’s how you must do it. We’ve fined-tuned hundreds of voices for you.
One issue for voice cloning is one company gives you very little control over the process and the other gives you zero control. We will try to expose, perhaps not initially, but over time, settings around fine-tuning that you can control. What epoch would you like to use? You may prefer a slightly overfit sound, or perhaps a slightly underfit sound. There are a dozen options to adjust to tweak your perfect voice clone.
We also look forward to adding more canonical voices. These are voices that we believe fully represent the person of interest. It’s important to know that we provide these voices for research and entertainment purposes. If you try to monetize content created with our tools, you bear the risk of some big tech legal department or the person behind that voice being upset with you. We may open the voice generation process to a marketplace or community system. We haven’t seen those systems work too well in the past. You’re free to recommend voices we should be making canonical copies of in our Discord, or by emailing or posting at us on X. We read every post!
There are several places we can go from here. Tell us what you’d like to see, and we’ll be happy to try and deliver.